Have you ever heard of a company called Sandalwood Continental? The BVI-incorporated company has been involved in various well-reported money laundering schemes - but unless you’re a passionate oligarch-tracking freak, the answer is most likely: no. Sandalwood is linked to Sergei Roldugin, the childhood friend of Russian president Vladimir Putin. Given these connections, it’d probably be a good idea to avoid doing business with it.
Yet, even with the intensifying sanctions around Russia’s invasion of Ukraine, Sandalwood is not directly listed on any sanctions list. However, it’s been discussed in news reports and is even mentioned on Roldugin’s Wikipedia page. It’s part of an odd sector of knowledge: things we know about as an investigative community, but which aren’t available as structured data.
From an engineering perspective, this raises an interesting question: Can we use media reporting as a data source to identify sanctions-adjacent persons and companies? Finding answers to that question has been the goal of StoryWeb, an open source data mining application we’ve been prototyping for the past six months.
Facts, not sentiments
Using journalistic reporting as a source for compliance information is, of course, not a new idea. A lot of adverse media systems, however, focus on associating the entities named in an article with specific events or forms of misconduct. An article about an mining company, for example, might mention labour rights violations or the displacement of indigenous people and therefore result in a negative ESG risk score for the firm.
StoryWeb, on the other hand, is focussed on a slightly different type of analysis. Instead of sentiment, the tool is meant to search for entity connectivity. Entities in the system - people, companies, places - are linked with each other in terms of a fixed taxonomy of connection types: they might be family members or business associates; a person could own or control a company, and so on.
The idea behind this: build out the network of sanctioned and wanted individuals to include the second-tier entities that are used to hide and disguise illicit activity - the consiglieri, the offshore companies, the proxies and old school-friends.
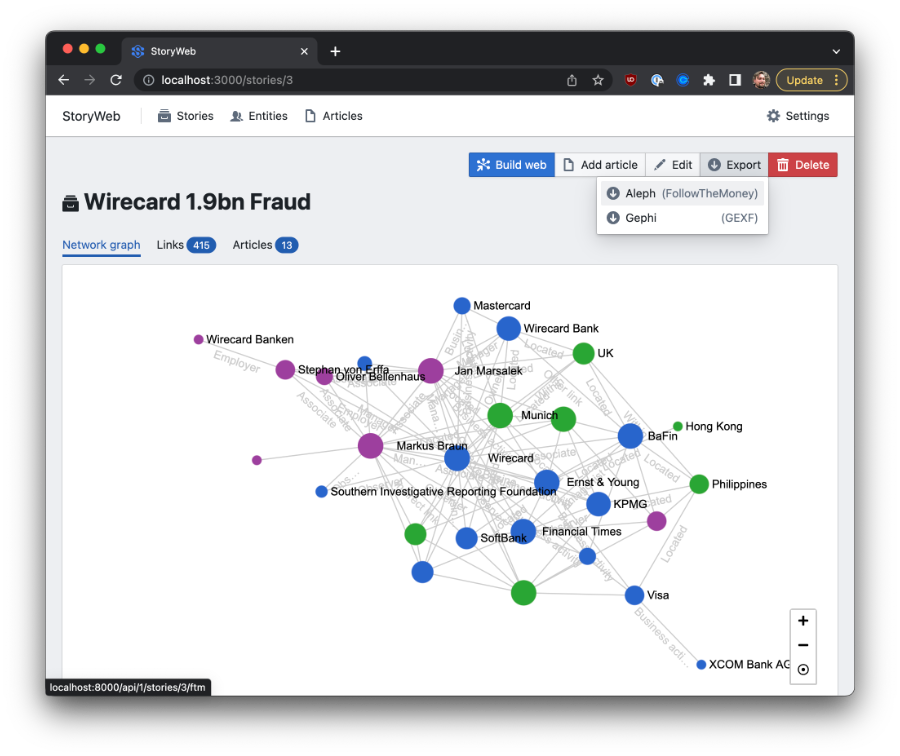
A story-specific network of entities related to a story that has been reported by the media.
Unfortunately, as you go away from speaking about the “big guys” to describing their facilitators, the problem of ambiguity of names becomes more serious: a news article about “Donald Trump” is likely to refer to the former US president, his former associate “Michael Cohen” is a much less unique descriptor - especially if you were to then try to match his name with other public records from the US. There’s hundreds and hundreds of people by that name.
Weaving a data graph
Inside of StoryWeb, networks are generated by building out “stories”: each a collection of articles related to the same topic or news event. A good example of a story might be the scandal surrounding German fintech/fraud Wirecard. While there are thousands of articles about the bank’s implosion, they all relate to the same set of individuals: the bank’s executives, their business partners and the critics that called their bluff.
In order to begin building out a story, an analyst will add news articles to it: either adding links manually via the user interface, or by picking articles from the archive of reporting crawled by mediacrawl, the StoryWeb component responsible for bulk importing of news media. As articles are added, the system will extract the names of companies and people mentioned in each text, and begin to keep score of which pairs of names most commonly co-occur in articles that form part of a story.
These pairs are then considered as possible relationships between the entities: if Wirecard AG and a person named Markus Braun appear together in 15 out of 20 stories related to the subject, perhaps there’s a connection?
Of course, the now-expected way of answering this question is to apply some form of machine learning that interprets the articles and makes a best guess as to the nature of the relationship. (In fact, you could do the same thing to build out topical themes in the first place: load a whole archive of articles and then have an algorithm cluster them into a set of stories.)
While this is what StoryWeb might do in the future, for now it’s using a different approach: ask an analyst. Analyst input has already served us well at OpenSanctions in designing our approach to entity de-duplication, so we designed an interface that prompts the user for possible relationships between two entities, a set of classification options, and a way to quickly dive into all the articles in which both entities are mentioned together.
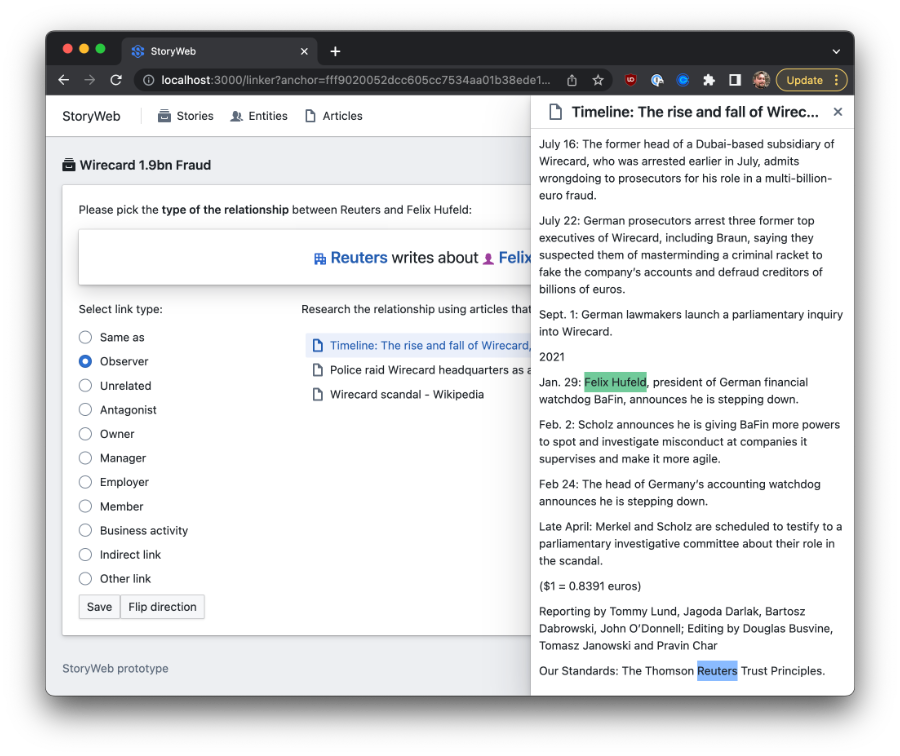
StoryWeb prompting an analyst to define the relationship between two entities by picking an option from a fixed ontology.
This human-in-the-loop approach is meant to provide two things: a reliable level of data quality, and training data for future, more automated approaches.
Noise over signal
Having built this “data loom” for us to weave story graphs from corruption stories, we got to the crucial moment of every data-driven exploration: facing the raw material. In our case, that’s a database of spaCy-extracted entity names from ca. 22,000 pieces of corruption-related reporting we chose as a working corpus.
The first things that make a grand entrance: names of geographic locations and media organisations. Both of these make intuitive sense: a lot of reporting references specific locations - whether it’s the location of a relevant event, or the nationality of one of the protagonists. And the names of other media organisations are commonly mentioned when articles describe the development of a story and what aspects had been reported previously. Also, everybody likes talking about themselves.
But even with those two categories of entities set aside, there’s a lot of work left to properly rank entity pairs that define the essential relationships of a story. Even with some normalisation to account for overall entity frequency, many of the pairs presented by our StoryWeb prototype seemed a little bit random and obvious. Tuning the order in which these pairs are prompted will be a significant area of future work in the tool.
Based on our use of the tool in the initial development period, we now have a training set of 5000 sentences extracted from articles that mention two entities and for which a classification is known. This material can not only be used to begin to develop an automatic classifier for relationship types, but perhaps it can also help us to identify sentences which are likely to define a relationship in the first place.
What’s next?
While StoryWeb has proven an instructive and fun experiment, we are not planning to bring StoryWeb-based inputs into the OpenSanctions data product this year. Our focus will instead be on fine-tuning the structured data sources of our offering, and we’ll only expand towards news media data once that aspect has seen much more maturation.
In the meantime, there’s two future developments for StoryWeb that we’re excited about: it’s uses outside of OpenSanctions, and the possible application of large natural language machine-learning models like ChatGPT to the problem of relationship classification.
We think that StoryWeb could, for example, be an interesting way for reporters and analysts to background a person or to familiarise themselves with a story they haven’t worked on before.
StoryWeb would prompt such users to systematically build out an understanding of the key relationships described in a set of articles, and reward them with a structured data extract of the resulting graph of entities - data they could then cross-reference against bulk datasets like leaked email archives or beneficial ownership databases. There’s also no reason why the input data for a StoryWeb instance needs to be news articles. Thanks to the articledata micro-format used to import text in bulk, you could easily load all the evidence and documents for a court case, or a historical archive, for example.
Sound useful? StoryWeb is, of course, open source software. Technical users can easily deploy the Docker container on their local machine or on a server and play with the tool there!
Finally, it’s early 2023 and we cannot conclude this blog post without referencing the AI mammoth in the room: ChatGPT. After a few experiments using OpenAI’s public testbed, we think that relationship classification (and thus actor graph building) may actually be one of the better discussed uses for systems like this.
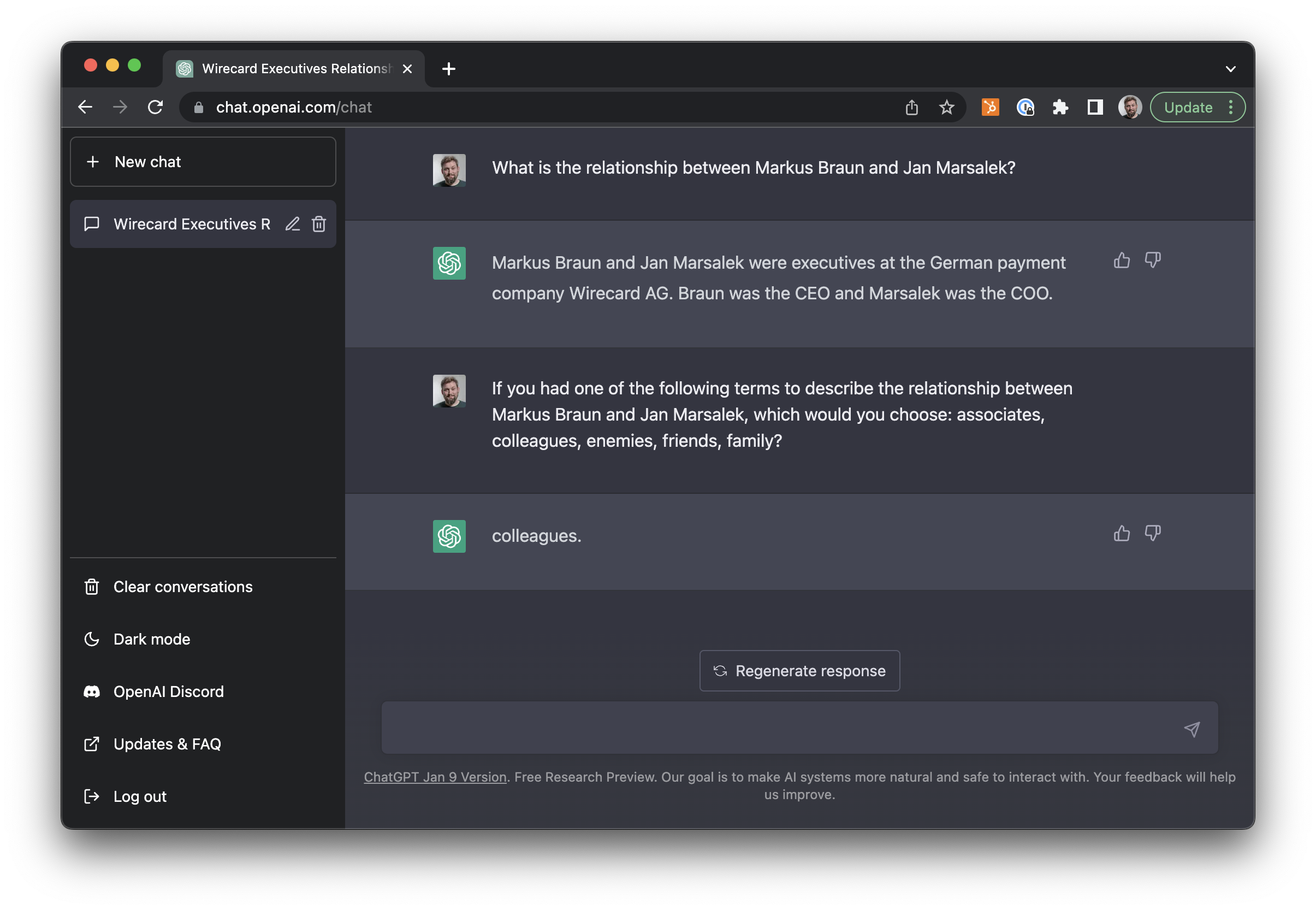
ChatGPT, the grandmaster of bullshit, might offer a viable approach for classifying relations between entities - a task that requires mainly summarization, not creative thinking.
While ChatGPT lacks any in-depth understanding of corruption or financial crime, it may address one problem particularly well: journalistic obscurantism. A lot of reporting on white collar crime is written in a form that’s not just meant to inform the reader, but also calm the heart rates of the publication’s legal department.
That’s how “the politician received a kickback” becomes “the payment to his company coincided in time with the grant of the procurement contract award”; mafiosi are referred to as businessmen; and obvious crime becomes “illicit behaviour”. Large language model systems may be good way of decoding this often formalised language and classifying it into a structured data graph.
